Large Language Models (LLMs) have transformed how organisations process information, generate content, and automate tasks.
Yet, one persistent challenge remains: how to adapt these powerful models for specialised tasks without sacrificing accuracy, efficiency, or reliability.
Two popular approaches have emerged: Retrieval-Augmented Generation (RAG) and Fine-tuning.
RAG enhances a model’s capabilities by allowing it to pull in external knowledge in real time, ensuring answers remain current.
Fine-tuning, on the other hand, trains the model on domain-specific data, embedding expertise directly into its parameters for consistent and reliable performance.
This article aims to help readers decide which approach to use depending on their goals, resources, and operational requirements.
We will explore the strengths, limitations, and ideal use cases of both RAG and fine-tuning, and highlight when a hybrid approach may offer the best results.
What is RAG (Retrieval-Augmented Generation)?
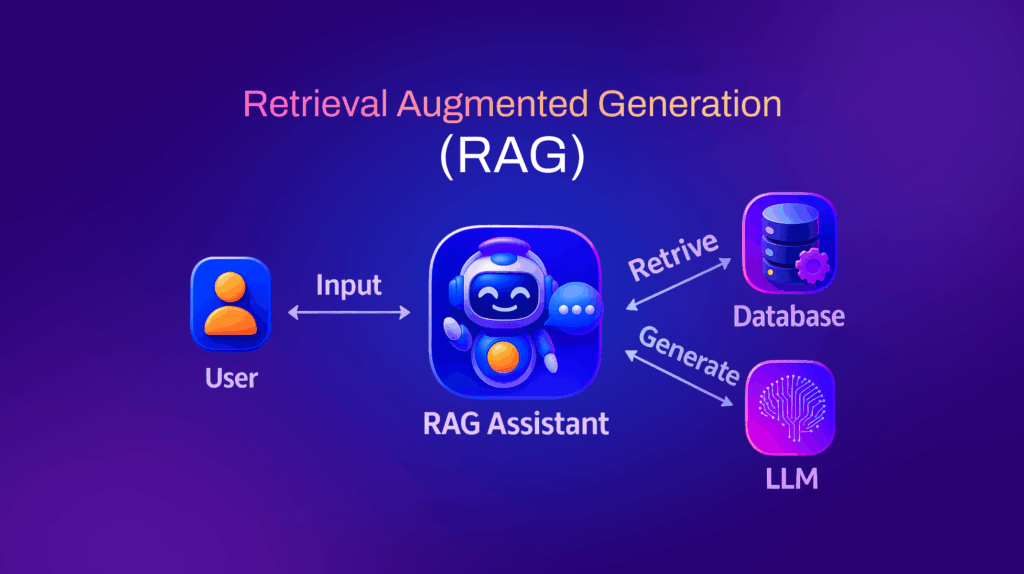
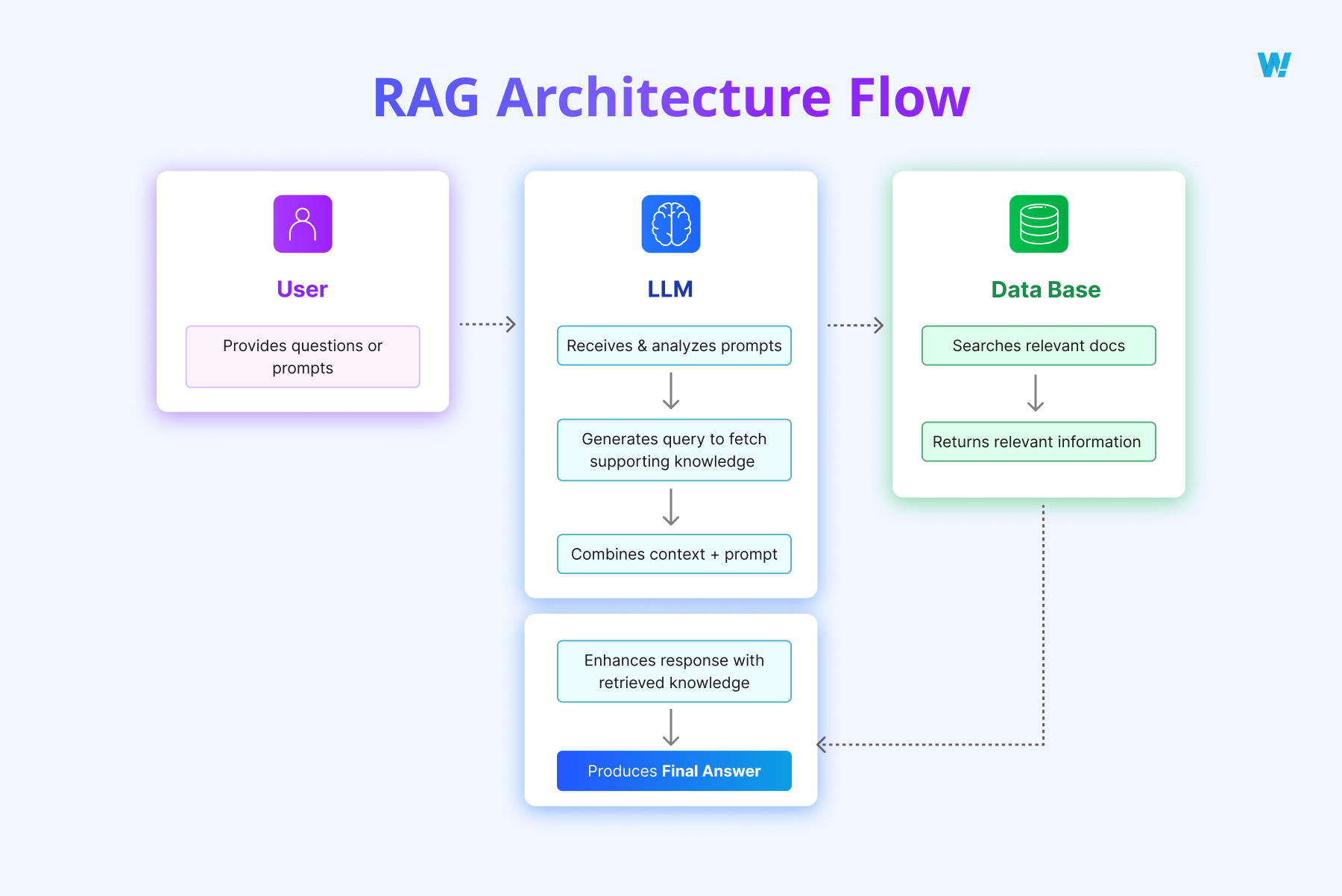
Retrieval-Augmented Generation (RAG) is an approach that strengthens Large Language Models (LLMs) by giving them access to external knowledge sources.
Instead of generating responses only from information the model learned during training, RAG allows it to search for relevant documents in real time and use that content to produce more accurate and reliable answers.
In other words, it combines the generative ability of LLMs with the precision of information retrieval.
How it works
The workflow behind RAG follows a clear sequence:
- User submits a query – A question or prompt is entered.
- LLM processes the query – The model converts the query into a vector (a mathematical representation).
- Search in external knowledge base – The system looks up the closest matches in a vector database or document store.
- Retrieve supporting information – Relevant documents, passages, or facts are pulled out and ranked.
- Inject context into the model – The retrieved content is added to the original query, creating a richer input.
- Generate final response – The model uses both the query and the external context to provide a grounded answer, often with citations.
This mechanism ensures that the LLM is not only creative but also factually aligned with the most relevant and up-to-date information.
Key advantages of RAG
- Always current – Since the knowledge base can be updated at any time, the model can reflect the latest information without needing retraining.
- Transparent and verifiable – RAG allows responses to include citations, enabling users to check the original sources.
- Scalable across sources – It can connect to multiple types of databases and document repositories, from websites to internal reports, making it versatile across industries.
What is Fine-Tuning?
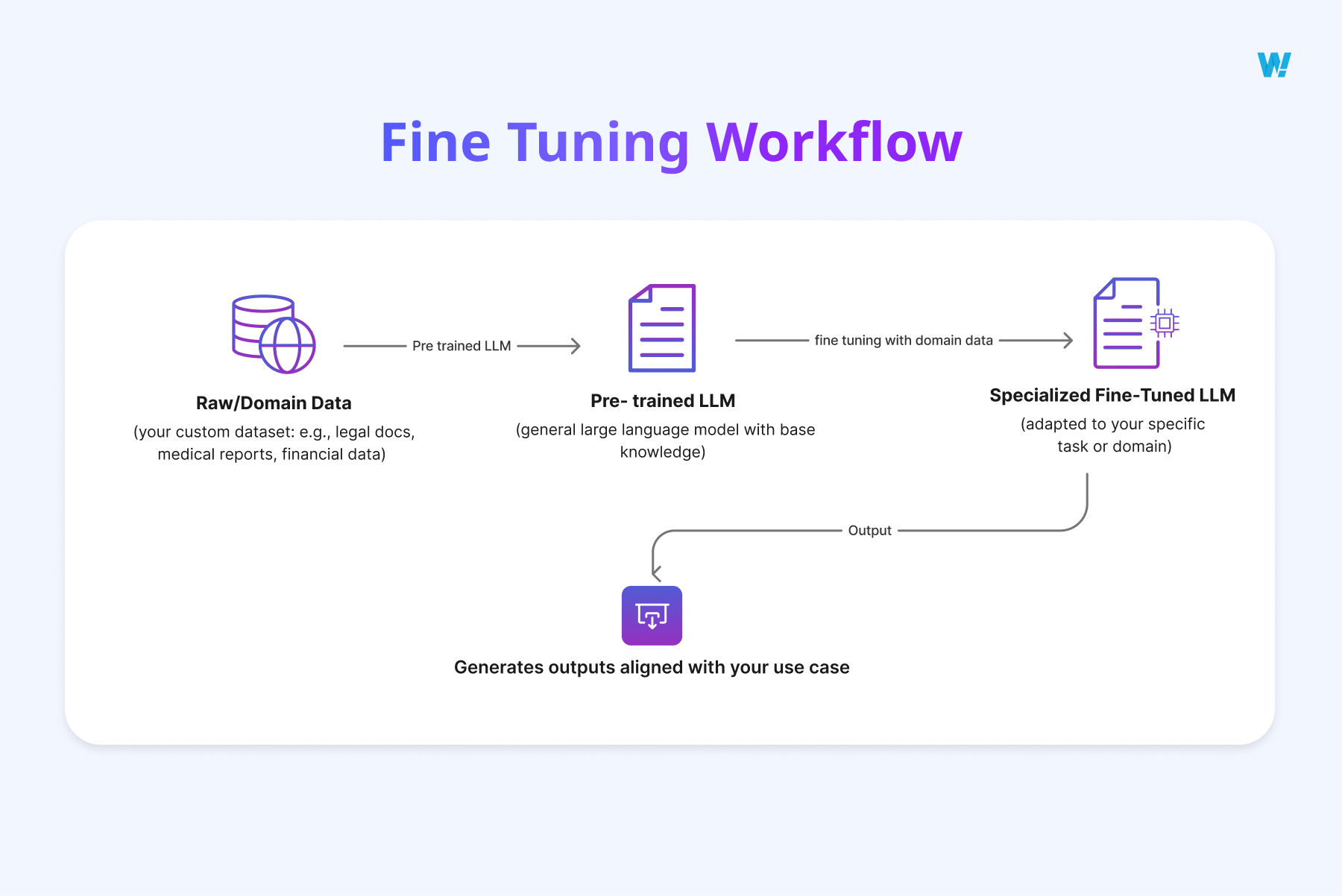
Fine-tuning is the process of adapting a base Large Language Model (LLM) to a specific domain, task, or style by retraining it on curated datasets.
Instead of pulling in external documents at query time, fine-tuning changes the model’s internal parameters so that the desired behaviours and knowledge are built directly into the system.
This makes the model more specialised, consistent, and aligned with the use case.
Methods of fine-tuning
- Full Fine-Tuning – All of the model’s parameters are retrained using the new dataset. This approach is powerful but also highly resource-intensive, requiring significant compute and time.
- LoRA / PEFT (Parameter-Efficient Fine-Tuning) – Instead of retraining the entire model, only a small subset of parameters are adjusted. This makes fine-tuning faster, cheaper, and more scalable, especially for large models.
- Instruction Tuning – Focuses on teaching the model to follow instructions more reliably by exposing it to many task-specific examples. This improves how well it understands prompts and generates responses aligned with user intent.
Key advantages of fine-tuning
- Domain expertise built-in – The model becomes fluent in the specialised vocabulary, style, and problem space of a given field (for example, law, medicine, or finance).
- High accuracy on structured tasks – Fine-tuned models perform especially well on stable and repeatable tasks, such as classification, extraction, or data formatting.
- Customised outputs – Organisations can shape the model to reflect their preferred style, tone, and terminology, ensuring brand or regulatory consistency.
- Reduced need for prompt engineering – Once the model is tuned, prompts can be shorter and simpler, as the desired behaviour is already encoded in the weights.
When to Use RAG
Retrieval-Augmented Generation (RAG) is particularly valuable in scenarios where information is dynamic, diverse, or too vast for a model to store internally.
By combining the generative abilities of LLMs with real-time access to external knowledge sources, RAG ensures responses remain current, accurate, and contextually relevant.
Ideal Use Cases
- Domains with rapidly changing knowledge
Fields like finance, law, healthcare, and news are constantly evolving. RAG allows models to access the latest regulations, stock movements, medical research, or news updates without retraining. This ensures that generated responses reflect the most recent information and maintain credibility. - Customer support chatbots requiring dynamic FAQs
Organisations often update their FAQs, policies, or product details. A RAG-powered chatbot can retrieve the latest information from internal documents or databases, providing accurate answers to users without needing a full model retraining. - Enterprise knowledge management
Large enterprises maintain extensive documentation, manuals, and internal resources. RAG enables employees to query these sources efficiently, surfacing relevant content across departments and repositories in real time. - Multi-domain applications where retraining isn’t feasible
In cases where a model must operate across multiple topics or industries, maintaining separate fine-tuned models can be impractical. RAG allows a single LLM to handle queries from various domains by fetching the right context on demand.
Practical Examples
- Financial market assistants – RAG can pull live market updates, regulatory news, or analyst reports, helping financial professionals make informed decisions.
- Internal HR chatbots – When company policies, leave rules, or benefits change frequently, RAG ensures employees receive up-to-date answers without retraining the underlying model.
- Research assistants – In academia or corporate research, RAG can retrieve the latest studies, papers, or datasets, giving researchers contextually rich and current information.
- Legal advisory tools – Lawyers or paralegals can query RAG-powered systems to access recent case law, regulations, and contract clauses without manually sifting through vast documents.
Why RAG is the Right Choice
RAG excels when freshness, transparency, and breadth of knowledge are crucial. Instead of retraining models every time data changes, it leverages real-time retrieval, allowing AI systems to remain relevant, scalable, and trustworthy.
When to Use Fine-Tuning
Fine-tuning is ideal when a model needs to perform consistently within a defined domain, follow specific rules, or adopt a particular tone. By adapting a base LLM to your data and requirements, fine-tuning ensures outputs are precise, reliable, and aligned with organisational standards.
Ideal Use Cases
- Static knowledge bases
Industries such as insurance, manufacturing, or logistics often rely on established rules, processes, and protocols. Fine-tuning allows the model to internalise these rules, producing accurate and repeatable results without relying on external retrieval. - Highly technical domains with specialised terminology
Fields like medicine, law, engineering, and scientific research have unique language, jargon, and conventions. Fine-tuned models become fluent in these terms, reducing ambiguity and improving precision. - Brand-specific tone and style
Marketing copy, customer communications, or public-facing content often require a consistent voice. Fine-tuning allows the model to generate outputs that reflect the company’s tone, style, and messaging guidelines, creating a cohesive brand presence.
Practical Examples
- Medical diagnosis assistant – A model fine-tuned on clinical datasets can provide reliable diagnostic suggestions, explanations, and structured recommendations for healthcare professionals.
- Legal document summariser – Fine-tuning on legal texts ensures summaries preserve compliance-critical wording, legal terminology, and required structure.
- Marketing content generator – A model trained on brand guidelines and previous campaigns can consistently produce copy that matches the company’s tone and style.
- Manufacturing process guide – Fine-tuning allows an AI assistant to provide step-by-step instructions, safety procedures, and troubleshooting advice tailored to a specific plant or equipment.
Why Fine-Tuning is the Right Choice
Fine-tuning excels when consistency, domain expertise, and output reliability are essential. Unlike retrieval-based approaches, the model’s knowledge and behaviour are embedded directly into its parameters.
This makes fine-tuned models highly accurate for structured, static, or specialised tasks, ensuring users receive dependable and repeatable results.
Hybrid Approaches (RAG + Fine-Tuning Together)
Why Combine the Two?
Neither RAG nor fine-tuning alone can solve every AI challenge. Fine-tuning gives a model deep domain expertise, but its knowledge is fixed. RAG provides access to up-to-date information but lacks embedded domain-specific behaviour.
By combining the two, hybrid systems deliver answers that are both accurate and current.
How the Hybrid Model Works
- Embedded Expertise – The model is fine-tuned to understand domain rules, terminology, and organisational style.
- Live Knowledge Access – RAG fetches relevant external information from knowledge bases, documents, or live data feeds.
- Integrated Response – The model generates answers by blending its internal expertise with the fresh context retrieved in real time.
Real-World Example
A banking chatbot illustrates this perfectly:
- Fine-tuned on internal policies, regulations, and compliance rules.
- Uses RAG to pull the latest interest rates, market updates, and regulatory announcements.
The hybrid approach ensures users get trustworthy advice that is also timely, combining the reliability of fine-tuning with the freshness of RAG.
Benefits of Going Hybrid
- Accuracy + Real-Time Updates – Deep knowledge meets live information.
- Flexibility Across Tasks – Can handle structured, static queries and dynamic questions alike.
- Improved Reliability and Trust – Responses are both grounded in expertise and verifiable with current data.
Evidence from Research
Studies on hybrid “Finetune-RAG” methods show accuracy improvements of 20% or more compared to using either approach alone.
This demonstrates the practical value of combining static domain knowledge with dynamic retrieval.
Key Differences Between RAG and Fine-Tuning
When deciding between Retrieval-Augmented Generation (RAG) and Fine-Tuning, the right choice depends on your goals, resources, and use case. Below is a side-by-side comparison across critical dimensions:
| Dimension | RAG | Fine-Tuning |
|---|---|---|
| Knowledge Freshness | Always current, as external knowledge bases can be updated instantly. | Static — knowledge is frozen at the time of training. |
| Domain Specialisation | Generalist — draws from external sources but not deeply embedded. | Specialist — expertise and terminology baked directly into the model. |
| Implementation Complexity | Requires infrastructure for vector databases, indexing, and retrieval pipelines. | Requires high-quality training data, compute resources, and ML expertise. |
| Performance Accuracy | Strong when tasks rely on factual recall or live knowledge. | Strong when tasks demand consistency, structure, or domain-specific precision. |
| Scalability | Easily scaled by connecting to multiple knowledge bases. | Scaling requires retraining and maintaining multiple versions of the model. |
| Cost | Lower upfront cost; no retraining needed. Ongoing cost for infra and storage. | Expensive to train, but cheaper long-term if the same tuned model is reused repeatedly. |
| Explainability | Transparent — supports citations and references to source material. | Opaque — behaves like a black box without clear source tracing. |
| Security & Compliance | Risk: unreliable or unverified external sources may slip in. | Risk: sensitive data used during training could leak or be memorised. |
Factors to Consider Before Choosing
Selecting between RAG, fine-tuning, or a hybrid approach is not just a technical decision—it depends on the nature of your domain, resources, and business requirements.
Here are the key factors to weigh:
1. Nature of the Domain
- Dynamic domains such as finance, news, or healthcare benefit from RAG, as information changes rapidly and models need access to the latest knowledge.
- Static domains like manufacturing processes or regulatory guidelines are better suited for fine-tuning, where consistency and adherence to established rules are critical.
2. Data Availability
Fine-tuning requires high-quality, labelled datasets to train the model effectively. If sufficient data is not available, RAG may be a more practical choice, as it relies on retrieval rather than retraining.
3. Budget and Resources
- Fine-tuning can be expensive upfront due to compute costs and data preparation, but it can pay off long-term if the same model is reused extensively.
- RAG has lower training costs but requires investment in infrastructure, such as vector databases, indexing pipelines, and storage for documents.
4. Latency Requirements
Fine-tuned models typically generate responses faster since no retrieval step is involved during inference. RAG introduces a retrieval overhead, which may affect response time in applications requiring instant outputs.
5. Compliance and Privacy
Sensitive or regulated data must be handled carefully. Fine-tuning stores knowledge within the model weights, which can create risks if proprietary or private data leaks. RAG relies on external sources, so the quality and reliability of the documents must be carefully managed.
6. Model Size and Capacity
- Smaller models often benefit more from fine-tuning, as they have limited capacity to store extensive knowledge.
- Larger models can effectively combine RAG and fine-tuning, leveraging retrieval to supplement their already rich internal knowledge.
Curious about RAG vs Fine-Tuning?
At Wow Labz, we guide teams in choosing the right approach to optimise LLMs, whether it’s retrieval-augmented generation for flexibility or fine-tuning for precision.
From pilot projects to enterprise-scale AI, we help you unlock the full potential of intelligent systems.




